Published on October 15, 2025
Add a robots.txt file to your Github pages.
Robots.txt file is useful for search engines to crawl your website easily and help to gain search engine optimization for your website.
1: Visit your Github repository and create a new file called robots.txt.
2: Enter below details and press commit changes.
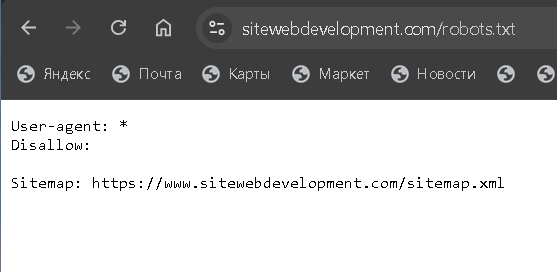
User-agent: *
Disallow:
Sitemap: https://www.yourdomain.com/sitemap.xml
Sitemap: https://www.yourdomain.com/image-sitemap.xml
Sitemap: https://www.yourdomain.com/video-sitemap.xml
3: To ensure that robots.txt file is working you have to type https://www.yourdomain.com/robots.txt in the browser.
Note: To build a databases of web pages search engines will send their robots or seos, we will call them spiders to scan web pages and gather information. And that process is called crawling. When these robots visit a side, they wil read the directive of the website called robots.txt. this document will tell search engines which pages or sections of the website they are permitted to visit and which should be avoided.
For more information
If you want more information about how to use robots.txt file, check out the StackOverflow guide which describes GitHub Pages indexing. .